USENIX Security 2025
CAMP in the Odyssey: Provably Robust Reinforcement Learning with Certified Radius Maximization
Certified-radius-maximizing policy training for robust deep reinforcement learning agents.
1CSIRO's Data61, Australia 2Cyber Security Cooperative Research Centre, Australia 3Deakin University, Australia 4University of Chicago, USA
Highlights
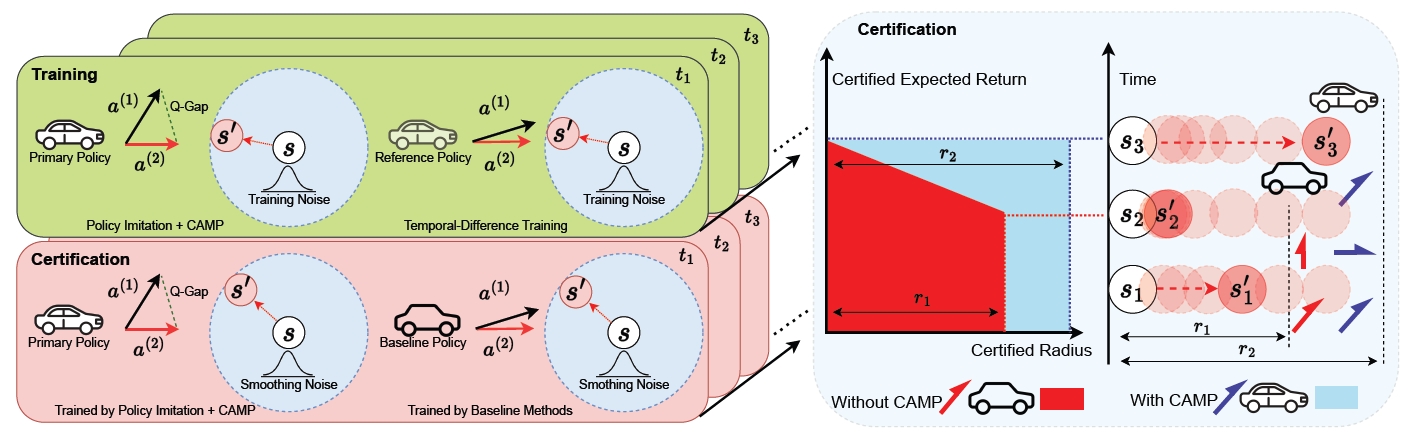
CAMP improves certified robustness for deep reinforcement learning by directly optimizing a training objective connected to certified radius.
Abstract
We introduce Certified-rAdius-Maximizing Policy (CAMP) training for certifiably robust deep reinforcement learning agents. CAMP improves the robustness-return trade-off by optimizing policies with a surrogate loss derived from certified-radius maximization.
The key insight is that the global certified radius can be derived from local certified radii based on training-time statistics. CAMP uses this relationship during training and introduces policy imitation to stabilize optimization.
Method
Local-to-global certification
CAMP links local certified radii observed during training to the global certified radius, allowing robustness to be optimized through a tractable policy-training objective.
Stable robust policy learning
Policy imitation provides a stabilizing signal, helping CAMP train agents that preserve utility while improving provable robustness.
BibTeX
@inproceedings{wang2025camp,
title={CAMP in the Odyssey: Provably Robust Reinforcement Learning with Certified Radius Maximization},
author={Wang, Derui and Moore, Kristen and Goel, Diksha and Kim, Minjune and Li, Gang and Li, Yang and Doss, Robin and Xue, Minhui and Li, Bo and Camtepe, Seyit and Zhu, Liming},
booktitle={USENIX Security Symposium},
year={2025}
}