
Publications
Selected Papers
[NDSS’25][ Distinguished Paper Award ] Provably Unlearnable Data Examples (Project | Paper | Code)
Derui Wang, Minhui Xue, Bo Li, Seyit Camtepe, Liming Zhu
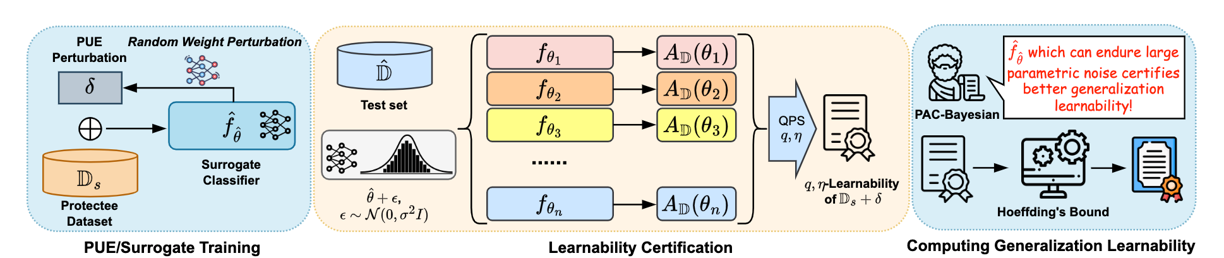
We introduce the theory of certified learnability in this paper. Certified $(q,\eta)$-Learnability measures how learnable a dataset is by computing a probabilistic upper bound on the test performance of classifiers trained on this dataset, as long as those classifiers fall within a certified parameter set. We use certified $(q,\eta)$-Learnability as a measurement of the effectiveness and robustness of unlearnable examples, and propose Provably Unlearnable Examples (PUEs) which can lead to reduced $(q,\eta)$-Learnability when training classifiers on them.
[USENIX Security’25] CAMP in the Odyssey: Provably Robust Reinforcement Learning with Certified Radius Maximization (Project | Paper | Code)
Derui Wang, Kristen Moore, Diksha Goel, Minjune Kim, Gang Li, Yang Li, Robin Doss, Minhui Xue, Bo Li, Seyit Camtepe, Liming Zhu
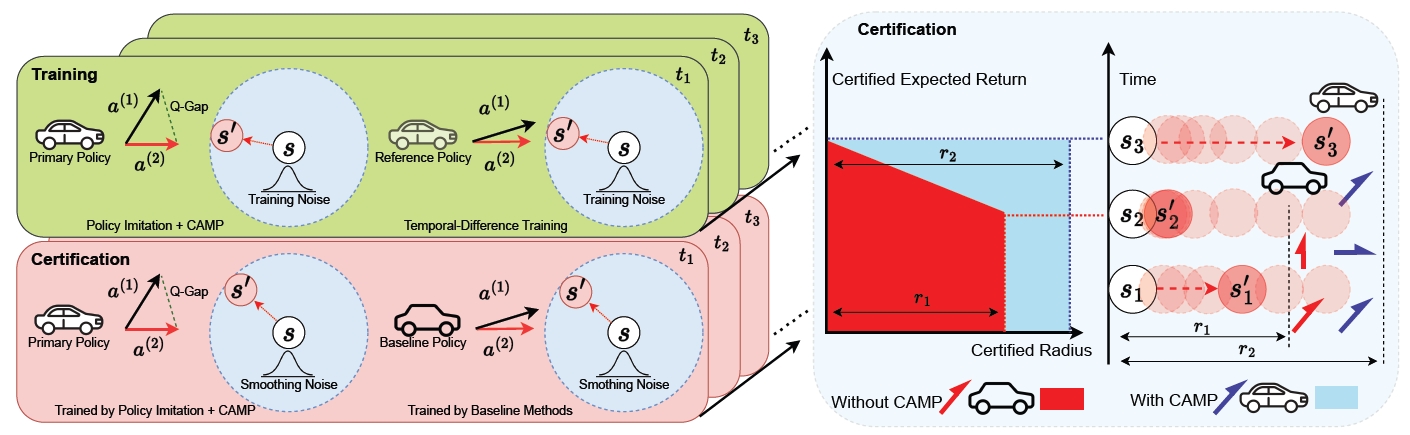
We introduce a novel paradigm dubbed {C}ertified-r{A}dius-{M}aximizing {P}olicy (CAMP) training for certifiably robust deep reinforcement learning (DRL) agents. CAMP is designed to enhance DRL policies, achieving better utility without compromising provable robustness. By leveraging the insight that the global certified radius can be derived from local certified radii based on training-time statistics, CAMP formulates a surrogate loss related to the local certified radius and optimizes the policy guided by this surrogate loss. We also introduce policy imitation as a novel technique to stabilize CAMP training. Experimental results demonstrate that CAMP significantly improves the robustness-return trade-off across various tasks. Based on the results, CAMP can achieve up to twice the certified expected return compared to that of baselines. Our code is also available at Zenodo.
[ICML’24] Effects of Exponential Gaussian Distribution on (Double Sampling) Randomized Smoothing (Paper | Code)
Youwei Shu, Xi Xiao, Derui Wang, Yuxin Cao, Siji Chen, Minhui Xue, Linyi Li, Bo Li
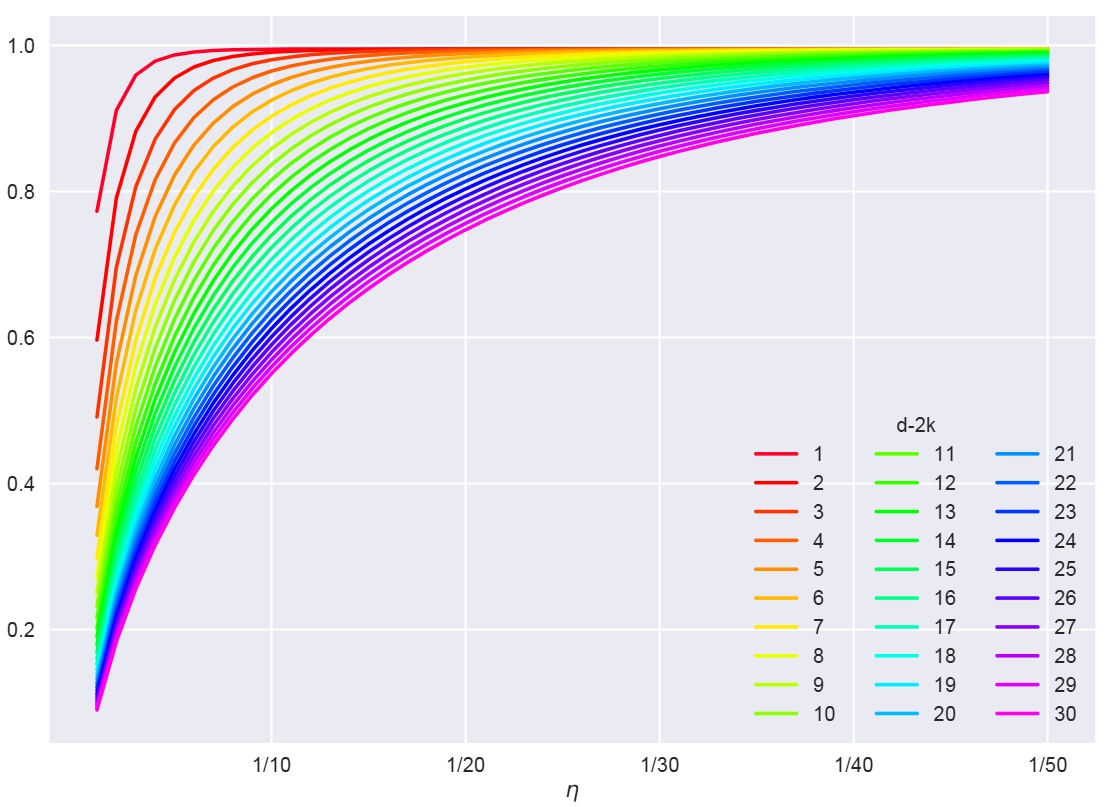
We address in this paper the curse of dimensionality of Randomized Smoothing (RS). RS is currently a scalable certified defense method providing robustness certification against adversarial examples. Although significant progress has been achieved in providing defenses against $\ell_p$ adversaries, the interaction between the smoothing distribution and the robustness certification still remains vague. In this work, we comprehensively study the effect of two families of distributions, named Exponential Standard Gaussian (ESG) and Exponential General Gaussian (EGG) distributions, on Randomized Smoothing and Double Sampling Randomized Smoothing (DSRS). We derive an analytic formula for ESG’s certified radius, which converges to the origin formula of RS as the dimension $d$ increases. Additionally, we prove that EGG can provide tighter constant factors than DSRS in providing $\Omega(\sqrt{d})$ lower bounds of $\ell_2$ certified radius, and thus further addresses the curse of dimensionality in RS. Compared to the primitive DSRS, the increase in certified accuracy provided by EGG is prominent, up to 6.4% on ImageNet.
[USENIX Security’25] SafeSpeech: Robust and Universal Voice Protection Against Malicious Speech Synthesis (Paper | Code)
Zhisheng Zhang, Derui Wang, Qianyi Yang, Pengyang Huang, Junhan Pu, Yuxin Cao, Kai Ye, Jie Hao
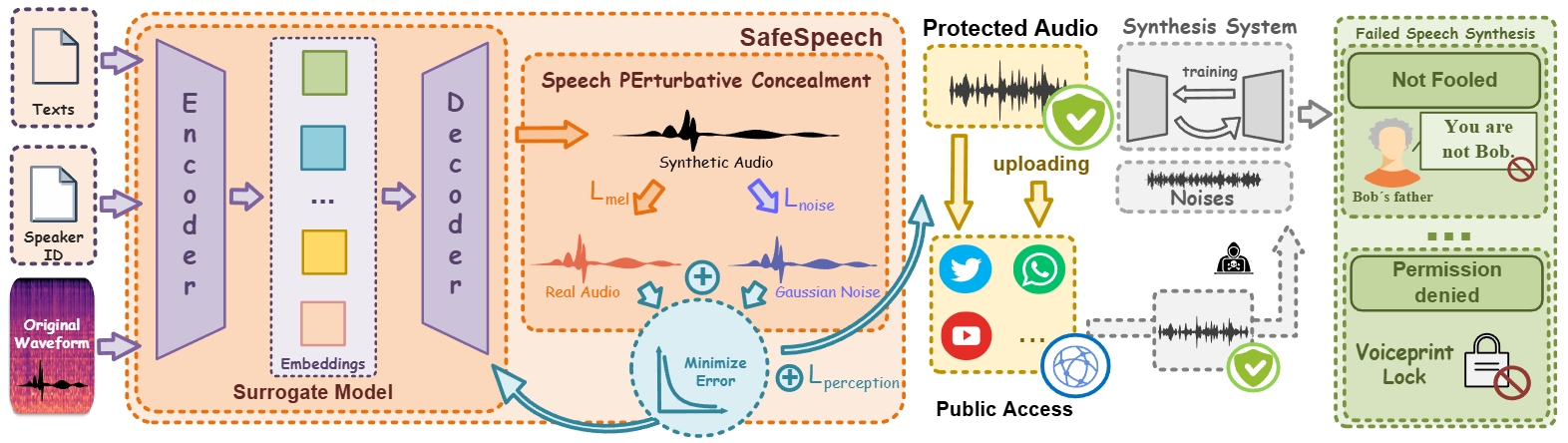
Speech synthesis technology has brought significant convenience, but the widespread use of realistic deepfake audio has also introduced considerable hazards. In particular, models trained on large-scale speech corpora can now generate highly realistic audio. By fine-tuning pretrained models, attackers require only a few minutes of speech samples to synthesize high-quality speeches with realistic timbre, rhythm, and phonemes. For example, criminals have used deepfake speech to impersonate a German executive, tricking a British subsidiary head into transferring $243,000.
In response, we introduce SafeSpeech, a method designed to protect users’ audio prior to publication by embedding imperceptible perturbations into the original speeches, thereby preventing the synthesis of high-quality deepfake audio. SafeSpeech achieves SOTA voice protection effectiveness and transferability and is highly robust against advanced adaptive adversaries. Importantly, in real-world tests, SafeSpeech demonstrated real-time capability by providing continuous protection for streaming audio data after a 14-second warmup.
[NDSS’23] The “Beatrix’’ Resurrections: Robust Backdoor Detection via Gram Matrices (Paper | Code)
Wanlun Ma, Derui Wang, Ruoxi Sun, Minhui Xue, Sheng Wen, Yang Xiang
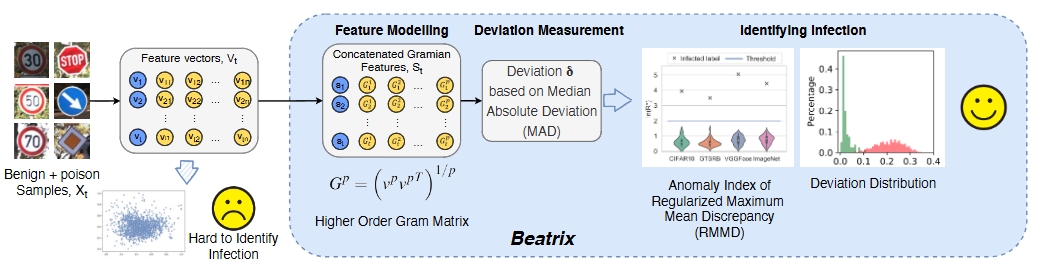
We propose Beatrix (backdoor detection via Gram matrix) as an effective detector against dynamic backdoors. Beatrix utilizes Gram matrix to capture not only the feature correlations but also the appropriately high-order information of the representations. By learning class-conditional statistics from activation patterns of normal samples, Beatrix can identify poisoned samples by capturing the anomalies in activation patterns. To further improve the performance in identifying target labels, Beatrix leverages kernel-based testing without making any prior assumptions on representation distribution. We demonstrate the effectiveness of our method through extensive evaluation and comparison with state-of-the-art defensive techniques. The experimental results show that our approach achieves an F1 score of 91.1% in detecting dynamic backdoors, while the state of the art can only reach 36.9%.
[SP’23] StyleFool: Fooling Video Classification Systems via Style Transfer (Paper | Code)
Yuxin Cao, Xi Xiao, Ruoxi Sun, Derui Wang, Minhui Xue, Sheng Wen
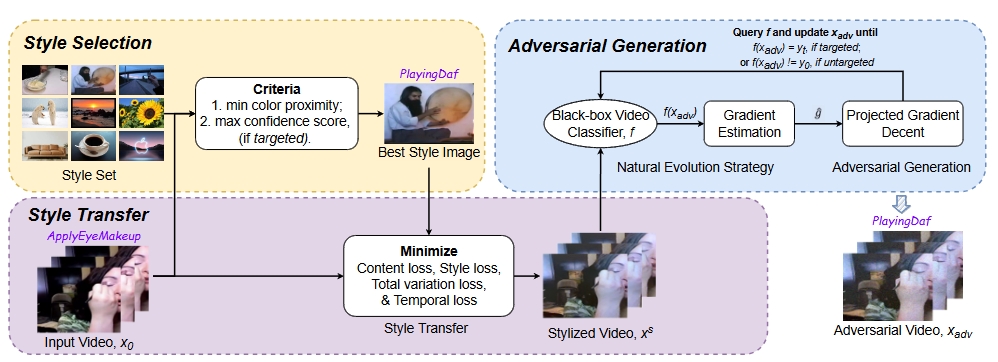
Video classification systems are vulnerable to adversarial attacks, which can create severe security problems in video verification. Current black-box attacks need a large number of queries to succeed, resulting in high computational overhead in the process of attack. On the other hand, attacks with restricted perturbations are ineffective against defenses such as denoising or adversarial training. We proposed StyleFool in this paper a gradient-free red-teaming method to evaluate the robustness of video classification systems. Leveraging style-transfer, our perturbations are crafted to be more indistinguishable for human auditors. Moreover, StyleFool outperforms the state-of-the-art adversarial attacks in terms of both the number of queries and the robustness against existing defenses.
List of Publications
The list of my publications can also be found on my Google Scholar.